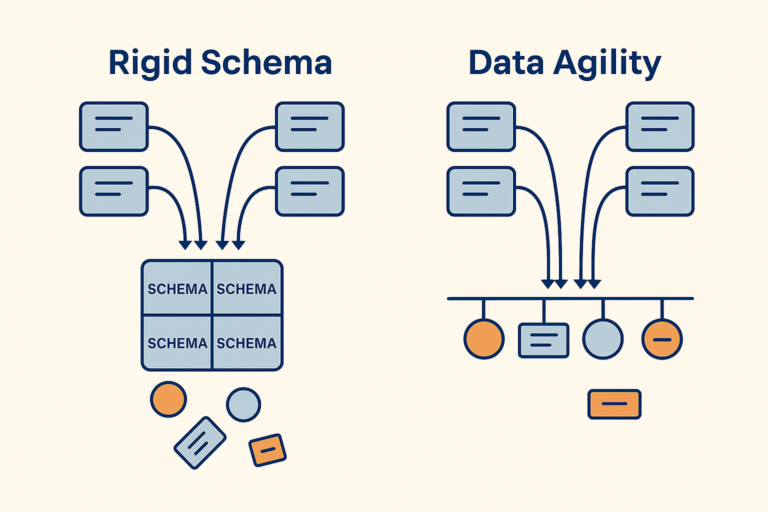
Software Development in the Age of AI

What does it mean to be a software developer at a time when AI can write code? I’ve been experimenting with AI tools to answer that question for myself. I’ve found what others have concluded: LLM-powered AI tools can be…