This is part of a draft of MarkLogic 8 for Node.js Developers. Incomplete sections are [marked with brackets].
MarkLogic databases represent all data as documents, using JSON, XML, text, and binary formats. Representing data as documents is fundamental to understanding how MarkLogic works. To fully understand MarkLogic, we’ll also have to address semantic triples. This chapter will focus on documents, but we’ll revisit data modeling in the Semantics chapter.
[XML: markup, namespaces. JSON: data structures. Text: content, but no structure. Properties fragments.
Modeling: iterative. Load as-is, modify as needed. ]
Data Modeling
Relational databases model data using a schema, which is a group of tables that describe the data. Tables have fields to represent types of information and each row represents an item. Figure 3 shows an example of a simple relational schema for a book database.
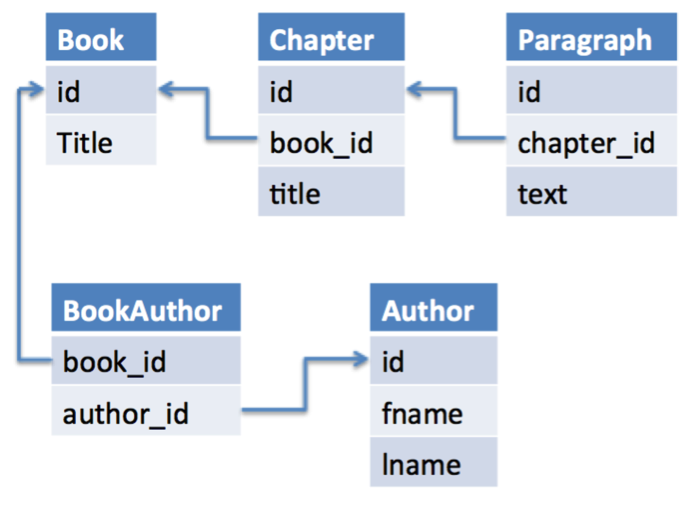
These tables have rows, where (in this case) each row represents a book. Figure 4 shows some rows in that schema (leaving out the Paragraph table for brevity). Foreign keys provide links among the various tables, showing how they relate to each other. Rows from different tables connect by way of these foreign keys, building a network of data that represents something.

Document databases represent information hierarchically instead of using a tabular approach. This approach can be used to represent a wide variety of data, in many cases including data that is stored in relational tables. Imagine the foreign key relationships as physical strings connecting rows. If you take hold of row 3 in the Book table and pull, the strings will draw other rows from other tables, giving you a structure like that in Figure 5.
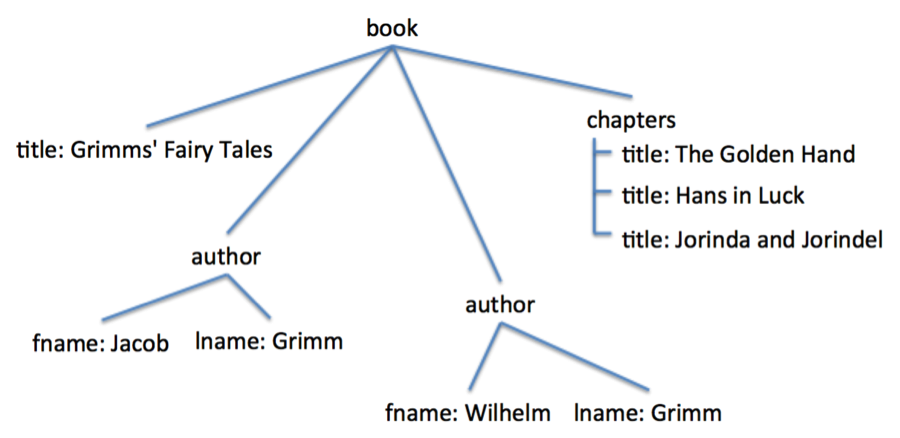
This hierarchical structure can be represented using either JSON or XML, both of which are stored natively in MarkLogic.
Listing 2: JSON representation of a book
The key insight here is that one row in a relational database is analogous to a document in a document database.
A JSON or XML document is uniquely identified within a database with a Uniform Resource Identifier (URI). The URI for a document is analogous to the primary key in a relational table and may consist of a human-readable title or just a unique value. For instance, the book in Listing 2 might be stored at “grimms-fairy-tales.json” or at “3e55746aefcd903732329abe7d114536.json”.
We can go further by using directories to organize data, which are reflected in URIs by the slash (“/”) character. For instance, we might see “/books/grimms-fairy-tales.json”, or “/searchable/source1/item3.json”. In the book example, there are two directories: “/” and “/books/”. A directory name always ends with a slash. As with directories on a file system, MarkLogic directories are hierarchical and a file exists in only one directory.
Schema Design
Relational databases require a lot of work early in a project to determine the schema. The database designer must determine what the tables will be, what fields they will have, how those tables will relate to each other, and what types the fields will have. Doing this well is skill in itself, requiring a deep understanding of an application’s requirements and an ability to anticipate the cardinality, type and relationship of each of the fields, in addition to general knowledge about how to map this onto a schema. This work needs to be completed before any substantial work can begin on an application. In practice, requirements change, often requiring changes in the schema.
With a document-oriented database, a developer will spend time considering how to represent data, but this time tends to be dramatically less. In cases where there is an existing data set, particularly if the data are available as JSON, XML, or even CSV[1], the data can be loaded with minimal work. If the documents are binaries such as Office, PDF, image, or audio files, MarkLogic ships with a library to extract text and metadata and format them as XML. In these situations, the developer can very quickly begin work on the application, allowing the discovered needs of the application to drive the data modeling process.
Some people object to this approach, saying that you cannot build an application until you understand the data. This criticism represents Waterfall thinking. In practice, software developers have seen that regardless of how hard they try to anticipate the needs of an application, new requirements will emerge, priorities will change, and new data sets may be needed. Developers do need to understand the data, but this can be done iteratively, adjusting the data model as needed. This adjustment happens much more easily in a document context than in a relational one.
Progressive Enhancement
This iterative effort is known as Progressive Enhancement. Data can be loaded “as-is” allowing developers and other stakeholders to explore the data within the database itself. As clarity about the data requirements emerges, the data itself can easily be modified.
An important benefit from working this way is that decisions about data types, and the work to convert input data to match those types, can be deferred until there is a compelling need from the application. [Present an example of this, preferably based on Samplestack. Talk about seed data from Stack Overflow. What format did we get it in? How was it loaded (or could it have been loaded)?]
In other cases, the developer needs to determine the document structure. There are some useful guidelines for figuring this out. Before we get into that, we need to examine the next topic: denormalization.
Denormalization
Relational databases normalize data to some degree; that is, rather than repeating a piece of data in multiple rows, a table that needs that information will store a foreign key pointing to another table that holds the data. For instance, rather than storing a publisher’s name in a book table, publisher information will be stored in a publisher table, with the book table storing the key of the publisher that published a particular book. There are benefits to this approach, such as knowing that an update to the publisher’s information will only need to happen in one place.
On the other hand, this process means that data is typically shredded from its original form to fit into tables, and then reassembled at run time by joining tables in response to a query. This becomes particularly expensive as the data set grows and the data need to be partitioned among multiple database servers (this process is known as sharding).
Document databases take a different approach, denormalizing data. This means that at least some information about a publisher will be included in each book document that the publisher brought to market. The idea is that all information needed to determine whether a document matches a query is contained within the document, avoiding the need for joins.
This does not mean that all information about a publisher needs to be repeated in every book document. The developer will decide what types of documents are needed and what data will go into each.
Building a Data Model
There are several factors to consider when deciding what to include in a document.
Document databases can hold many types of documents
In a document database, documents that represent different types of entities can sit side by side. A book database might have separate documents for books, authors, and publishers, each containing the bulk of information related to that type.
A document is the unit of search
When doing a search against a MarkLogic database, the typical goal is to identify which documents match a particular query. Understanding what an application’s users will want to search for informs the types of documents you should have.
Include what will be searched for
When considering a book database, a user might want to search for books by a particular publisher, but will probably not be looking for books published by a company based in a particular region, or founded in a certain year. Such information can be left out of the book document — it will not contribute to search, so there is no benefit to repeating it. Repeating the publisher’s name in book documents makes more sense. Data that is more helpful when searching for publishers will be included in publisher documents.
Don’t repeat what will be updated often
Pieces of data that will change often should be normalized. For example, a publishing company’s name will not change often, and therefore could be denormalized into other documents if searching on it is important.
Dynamically calculate values that will change quickly
How many books has an author sold? The answer is the sum of the sales of each book the author has published. The essential data is the per-book sales. The total will change frequently; storing the total will lead to frequent updates and a need to work at the application level to ensure the number stays correct. Conversely, the total is easy to calculate at run-time and can be done very quickly using indexes.
Size documents appropriately
In MarkLogic, the ideal document size is in the range of 10 kilobytes to 1 megabyte. Larger documents take time to read from disk when they need to be retrieved. Very small documents are less efficient, since there is some overhead introduced for each document.
Choose JSON or XML, or a mix
In some ways, the choice between JSON and XML is a matter of preference. For a Node.js developer, JSON is a very natural choice, as JSON and JavaScript are so closely related. This book will focus on JSON.
If there is a starting data set that uses XML, the developer may choose to keep it that way in the database, but transform to JSON in response to requests for data.
There are some differences in what can easily be represented in JSON versus XML. XML is good for text that will be marked up. For instance, consider a document that will be passed to an entity extraction engine to identify person names, locations, organizations, dates, and other information. In some cases, we just want to know that these things exist within a document, in which case we can store it in JSON. However, if we want to mark up the document inline, so that we can later look for entities near each other, XML handles this well. XML also allows for attributes, which describe elements, as well as indicating that a document is in a particular language.
Figure 6: Example XML data showing markup
Overall, XML is an expressive format for representing content (text in a hierarchical structure), while JSON is good for data — key/value pairs, arrays, and other data that consists of scalar data at various levels of the document hierarchy.
MarkLogic is schema-agnostic
Relational databases require a schema to describe data. XML documents stored in MarkLogic may be required to adhere to an XML schema, but this is optional. In most cases, no formal schema is used and documents with different, informal schemas exist within a database. This flexibility is what is meant by schema-agnostic. MarkLogic contrasts that with “schemaless” databases, which do not provide the option to require a schema.
Schemas for JSON have not been formalized by standards bodies to this point and MarkLogic does not support requiring a schema for JSON documents. That said, json-schema.org presents a schema approach that has a good following. A tool like jsen can be used to validate JSON documents against a JSON schema; just be aware that this will be an application-level process[2].
MarkLogic supports two-stage queries
Although MarkLogic documents are typically denormalized, sometimes a query requires some data from one type of document to query a different type of document. Data modeling in MarkLogic seeks to minimize this, but when necessary, an application can do a two-stage query. This is effectively a join and avoided where practical for the same reasons it is problematic for relational databases — two stage queries are necessarily slower than a single-stage query.
Samplestack Data Model
The Samplestack application provides an example of applying these principles.
In Samplestack, there are a few different entities in the application: Contributors, Questions, Answers, and Comments. Of these, users will search for questions and the answers that go with them. Comments form a natural part of the Questions and Answers that they are attached to. Finding an answer has little value without the question that it connects to. These considerations led to the QnA Document within Samplestack — a type of document that has Questions, Answers, and Comments. This is separate from the Contributor documents. Listing 3 shows a sample QnA document.
Listing 3: QnA document
Contributor documents, such as that in Listing 4, hold information about the users in Samplestack: a description, display name, unique identifier, user name, reputation, vote count, and website URL. Within the Samplestack user interface, we can search for questions, answers, or comments. To support that feature, a contributor’s display name and unique ID are denormalized into the QnA documents, with the document structure showing whether the individual wrote the question, an answer, or a comment.
Listing 4: Contributor document
Samplestack also allows users to up- or down-vote high-quality answers. When that happens, the answer within the QnA document gets updated, adding the voting user’s unique ID to the upvotingContributorIDs or downvotingContributorIDs. In addition, the reputation of the person receiving the up- or down-vote gets adjusted, along with the voteCount of the user casting the vote.
This change happens in the Contributor document. These last two points illustrate a principle of how far to take denormalization. If a Contributor’s reputation were denormalized into every QnA document where he or she had written a question, answer, or comment, then many documents would need to be updated every time the Contributor’s reputation changed. Reputation is expected to change frequently, which would lead to frequent widespread changes in the database. Instead, this information is kept in a single place: the Contributor document. To display this information along with QnA document data, we can read it separately from a Contributor document.
Samplestack Data Format
MarkLogic supports four data formats: JSON, XML, text, and binary. Samplestack uses JSON to store both QnA and Contributor documents. JSON was chosen over XML for a few reasons: the advantage of using JSON throughout the stack and Samplestack’s use case not requiring what XML has to offer.
By using JSON, the data format used in the database, the Node.js middle tier, and in the user interface code is the same. This eliminates the need to transform the data as it moves from layer to layer. Looking at the Contributor document in Listing 4, we can see a Java class name: com.marklogic.samplestack.domain.Contributor. This relates to the Java version of Samplestack, which allows easy storage of plain old Java objects (POJOs) as JSON documents with very little effort. For the Node.js version, we simply ignore that value.
Organizing Data
MarkLogic provides two ways to segment the documents within a database. The first of these is a directory structure, analogous to the directory structure on a file system: a document may be in only one directory, and directories may be nested. Documents can also be organized by putting them into collections. A document may be in many collections or none. Collections are independent of each other.
| Directories | Collections |
|---|---|
| Hierarchical | Independent |
| Name ends with / | Name is a URI |
| Document can only be in one | Document can be in many |
| Can query for documents that exist within a directory or its decedents | Can query for documents that are in a collection |
Loading Data
A common task at the beginning of a project is the ingestion of data. Data might be available in many forms. Within MarkLogic, documents will use one of four formats: JSON, XML, text, or binary. MarkLogic provides a few tools to load data and, if needed, transform the data.
MarkLogic Content Pump
The MarkLogic Content Pump (MLCP) is a company-supported tool for moving data into, out of, and between MarkLogic databases. MLCP is usually the simplest way to load data. This tool can be used to import XML, JSON, binary, text, aggregate, delimited text, and RDF files. For example, suppose “data” is a directory that holds a set of JSON files.
Figure 7: Example of using MLCP to import data
The host and port parameters identify an application server running on MarkLogic. Each application server is associated with a content database. Out of the box, MarkLogic has an application server running on port 8000, which uses a database called “Documents” for its content database. The example in Figure 7 can be changed using the “-database” to specify a different database to use. In this case, the command has been run with the admin user, which has rights to do anything. In the case of a real application, a user with just enough permissions for the task would be used (and the admin user would have a more secure password).
While it is common to load data as it exists and transform as the application evolves, sometimes the developer knows up front that some changes will be needed.
[MLCP. Transforms. CPF. How does Samplestack load data? Consider moving all the transform stuff to a different, later chapter. Focus here on just getting data into MarkLogic. ]
Content Processing Framework
MarkLogic provides a pipeline mechanism for transforming data. The Content Processing Framework (CPF) acts as a state machine, moving documents from one state to another.
An example of how CPF is sometimes used is the processing of binary data. Consider the case of loading a group of PDF documents, as shown in Figure 8. Once configured, CPF will see when a new PDF document is loaded into the database and call the “filter” process on it. Filtering finds text and metadata inside the document and produces a new XML document to hold it. The PDF’s state is changed to “filtered”, which is the end of processing for that document. The new XML document will be created in the “initial” state, triggering CPF to call the “enrich” process on it. This process would call a third-party entity enrichment service, sending the text and receiving the entities (such as persons, organizations, and locations) found inside.
These entities would be recorded in the document as additional XML. The XML document would move to the “enriched” state, triggering CPF to call the “geocode” process. This process would look up each location in order to find latitude and longitude values, which would also be recorded in the document.

CPF is helpful because each document’s state is recorded in the database itself, right along with the document. There are some downsides, however.
CPF uses property fragments to record document state and any errors that happen during processing. A property fragment is a fragment that has the same URI as the document itself, but is managed separately internally. These fragments are used to maintain information about a document without changing the contents of the document. This is especially helpful when working with binary content.
Accessing or updating a property fragment uses different parts of the API, such as cts.propertiesFragmentQuery() for a search that targets information in a property fragment.
The downside to this is addition fragments in the database, which contribute some overhead. Many MarkLogic developers prefer to avoid CPF because of this overhead.
Another aspect people dislike about CPF is the complexity of setting it up. A CPF configuration consists of pipelines, which are XML files identifying entry and exit states, conditions that must be true for action to be taken, the priority of this pipeline, and what action is to be taken.
Despite these negatives, CPF is a useful and viable tool for modifying content as it is loaded. Content that fails to get through the pipelines is still in the database, along with information about errors that happened during processing.
Let’s take another look at the example of normalizing dates in content. In this case, we will assume that once documents have a normalized date, they should be moved into a collection called “searchable”. We will implement these two steps in one different pipeline, though they could be split into two.
Suppose our data look like this:
and our goal is to make it look like this:
We need to write a pipeline description, an action module, and a domain. The pipeline description will describe the conditions under which the action module will be called. The domain specifies what subset of documents in the database are eligible for the pipeline to run against.
Listing 5: A CPF Pipeline
Listing 5 shows an example pipeline configuration. The pipeline-name will be used to identify the pipeline. The interesting part is the state-transition. This section describes how a document will be changed. In order for this transition to run on a document, the document must be in the state listed in the state property. After executing, the document will move to either the success or failure state, depending on the result of the execute instructions. The condition module and options specify code to be run to see whether this action applies to a document. If the condition code returns true, then MarkLogic runs the action module, passing the document URI as a parameter.
Notice that there is also a priority property. A configuration may have two or more pipelines with the same starting state. In this case, MarkLogic uses the pipeline’s priority to determine which pipeline to run.
To deploy the pipeline configuration, we can POST it using the MarkLogic Management API, as shown in Listing 6. The pipeline configuration is deployed to the Triggers database. Any database may act as a triggers database for another; “Triggers” is built by default when MarkLogic is first set up. A content database must have a triggers database configured in order to use CPF.
Listing 6: Deploying the pipeline configuration
The pipeline specifies what code to run, but we still need a module that has that code.
Listing 7: The action module, transform-data.sjs
Listing 7 shows a JavaScript action module that will normalize the date and store it in a new JSON property, releasedOn. There are several interesting aspects to this code.
Line 1 calls the declareUpdate() function. This function tells MarkLogic that this module will make changes to the database; distinguishing between modules that will make changes (and therefore need write locks on documents) and those that do not make changes (and therefore only need read locks). The difference allows MarkLogic to run read-only modules faster. This works because of MVCC, explained [elsewhere].
Line 3 imports an XQuery module. XQuery and JavaScript are both available to work with for code that runs in MarkLogic, and each language can import modules written in the other. The XQuery functions in the cpf.xqy library module are available through the cpf object.
Lines 4 and 5 appear to be simple variable declarations. They are that, but CPF needs to pass information into this module. MarkLogic sets the values of uri and transition for you. [should they be var, or globals?]
The test on line 7 protects against race conditions, to make sure only one CPF process works on a document at a time. Assuming that passes, lines 9-13 are the heart of this action module — retrieving the document, converting the time using a standard JavaScript Date object, and writing the document back to the database. This functionality is surrounded with a try/catch block, just in case something goes wrong.
Lines 15 and 17 tell CPF the result of the processing. If everything went well, we call cpf.success and CPF will move the document to the success state; otherwise, we call cpf.failure and CPF records the error. In either case, the results are recorded in the properties fragment.
Listing 8 illustrates how to deploy the action module using curl. The URL refers to port 8000, which hosts an application server with the MarkLogic REST API. In the default configuration, the port 8000 application server, called “App-Services”, uses “Documents” as its content database and “Modules” to hold code that it will execute. When we run the command in Listing 8, transform-date.sjs is written to the Modules database with a URI of “/ext/cpf/transform-date.sjs”. Note the content type being specified: “application/vnd.marklogic-javascript”. This mime-type tells MarkLogic that the contents of this file are source code. Be sure to use –data-binary with curl; otherwise newlines get turned into spaces, causing syntax problems if you have any single-line comments.
Listing 8: Deploying the action module
The last piece is the domain. The first part of the domain to specify is the scope, which indicates what documents the CPF processing applies to. The choices are a directory, a collection, or an individual document. There are three properties in Listing 9 that show the scope: scope, uri, and depth. In this case, they represent the very broadest scope possible: all documents anywhere under the root directory.
A domain also specifies an evaluation context, which tells CPF where to find the modules referred to in the pipeline. In Listing 9, the eval-module property indicates the database where modules are held, and eval-root shows where to look in that database. If we combine that information with the action module listed in the pipeline (/ext/cpf/transform-date.sjs), we see that CPF will expect to find the transform-date.sjs module in the /ext/cpf/ directory of the Modules database.
can be done in Query Console, simply by writing code that applies the change. For changes across a larger data set, the tool to use is Corb[4].
Corb2
To use Corb, there are two modules to write. The first identifies the documents that need to have a change applied. The second applies the change to a single document.
[Show examples of applying a change in QC and of using Corb.]
Additional Resources
- MarkLogic Developer Site: Data Modeling Guidelines
- Content Processing Framework Guide
- MarkLogic University XML and JSON Data Modeling Best Practices On Demand video
[1] Comma-Separated Values; generically, spreadsheet-like data where the fields are separated by some fixed delimiter, such as a comma. When loading into a document database, each row typically becomes a document.
[2] Hat tip to Erik Hennum for investigating JSON Schemas and sharing his findings.
[3] The meaning of “a small number of documents” depends on the size of the documents and the complexity of the change being applied. The limiting factor is whether the changes can be made in a single transaction before that transaction times out.
[4] http://github.com/marklogic/corb2